
Boosting¶
Julián D. Arias Londoño¶
Profesor Asociado
Departamento de Ingeniería de Sistemas
Universidad de Antioquia, Medellín, Colombia
julian.ariasl@udea.edu.co
%matplotlib inline
Como vimos en la clase anterior, en Machine Learning los métodos de ensamble sigen la idea de entrenar múltiples modelos simples y combinar sus respuestas para producir un mejor resultado. A diferencia del Bagging en Boosting la combinación se hace de manera secuencial y no paralela:
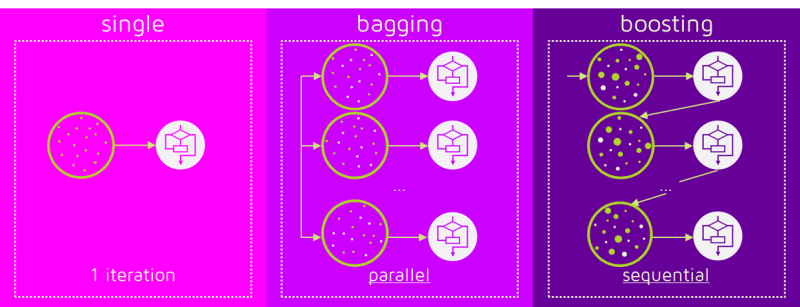
La idea central de los métodos de Boosting es entrenar modelos secuencialmente haciendo que los modelos subsiguientes se enfoquen en las muestras que no han podido ser modeladas correctamente por los modelos anteriores. Cada modelo tiene un peso diferente dentro de la decisión final. La forma de asignar el peso a las muestras y a los clasificadores dependen del método de Boosting particular.
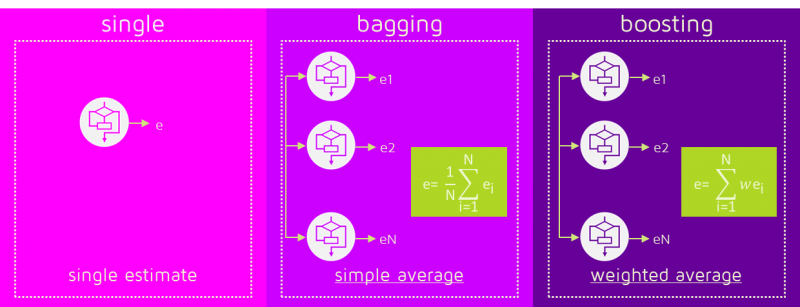
Imágenes tomadas de: https://quantdare.com/what-is-the-difference-between-bagging-and-boosting/
Los dos métodos reducen el error por varianza; boosting es mejor para reducir el bias pero puede presentar problemas de sobreajuste, razón por la cual algunos métodos de boosting requieren un ajuste cuidados de parámetros de regularización.
Adapting Boosting (Adaboost)¶
En Adaboost el modelo de ensamble se define como una suma sopesada de \(M\) modelos débiles:
donde \(\alpha_m\) son los pesos y \(f_m(\cdot)\) son los modelos base.
El algoritmo de entrenamiento consiste en adicionar clasificadores débiles uno a la vez, en un proceso de optimización iterativo, tratando de encontrar en cada iteración el mejor par \((\alpha_m, f_m)\) para adicional al ensamble actual.
Dado un conjunto de muestras de entrenamiento \(\mathcal{D} = \{({\bf{x}}_i,y_i)\}_{i=1}^N\)
Algoritmo AdaBoost
Inicialice los pesos de las muestras \(w_m(i) = 1/N\)
Para \(m\) desde 1 hasta \(M\)
Entrene un clasificador \(f_m: \mathbb{R}^d \rightarrow \{-1,+1\}\) teniendo en cuenta los pesos \(w_m\)
Estime el error \(\epsilon_m = \sum_{i:f_m({\bf{x}}_i) \neq y_i} w_m(i)\)
Estime el peso del clasificador \(\alpha_m = \log\frac{1 - \epsilon_m}{\epsilon_m}\)
Actualice los pesos \(w_{m+1}(i) = w_{m}(i)\exp(-\alpha_m y_i f_m({\bf{x}}_i))\)
El modelo obtenido será igual a \(F({\bf{x}}) = \text{sign}\left(\sum_{m=1}^M \alpha_m f_m({\bf{x}})\right)\)
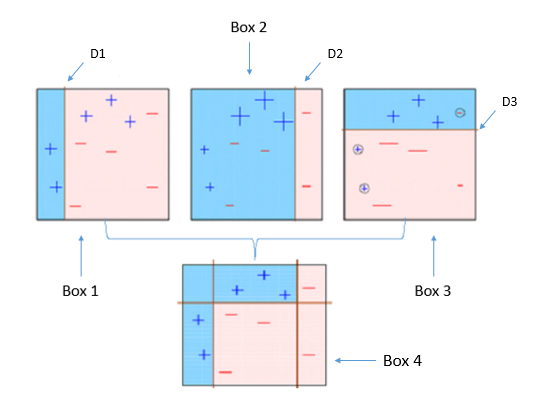
Imagen tomada de: https://towardsdatascience.com/understanding-adaboost-2f94f22d5bfe
Los pesos de cada una de las muestras dentro del algoritmo AdaBoost pueden ser tenidos en cuenta de dos formas:
Los pesos de cada muestra se pueden usar para establecer una nueva distribución \(D_{m+1}(i) = \frac{D_{m}(i)\exp(-\alpha_m y_i f_m({\bf{x}}_i))}{Z_m}\), donde \(Z_m\) es un factor de normalización que garantiza que la distribución cumplea la restricción estocástica \(\sum_{\forall i} D_{m}(i) = 1\). Se puede usar un proceso de muestreo sobre la distribución \(D_{m+1}\) en la cual tendrán mayor probabilidad de aparición las muestras sobre las que el modelo ha cometido más errores. Dicho muestreo se puede realizar fácilmente usando una distribución multinomial (numpy.random.multinomial).
Los pesos de cada muestra se pueden usar con clasificadores base que puedan tratar cada muestra con una importancia diferente. En el caso de los árboles de decisión, se puede, por ejemplo, usar el peso de cada muestra para medir la ganancia de información. Cuando se estima la probabilidad de quedar a cada lado de una partición \(a\), en lugar de contar 1 por cada muestra, se usa el peso de dicha muestra (sample_weight).
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import AdaBoostRegressor
import numpy as np
import matplotlib.pyplot as plt
# Create a random dataset
rng = np.random.RandomState(1)
X = np.sort(5 * rng.rand(80, 1), axis=0)
y = np.sin(X).ravel()
y[::5] += 3 * (0.5 - rng.rand(16))
# Fit regression model
from sklearn.tree import DecisionTreeRegressor
clf_b = DecisionTreeRegressor(max_depth=5)
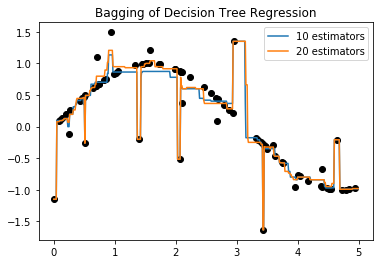
clf_1 = AdaBoostRegressor(base_estimator=clf_b, n_estimators=10, random_state=0).fit(X, y)
clf_2 = AdaBoostRegressor(base_estimator=clf_b, n_estimators=20, random_state=0).fit(X, y)
# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = clf_1.predict(X_test)
y_2 = clf_2.predict(X_test)
plt.plot(X,y,'o',color='black')
plt.plot(X_test,y_1,label='10 estimators')
plt.plot(X_test,y_2,label='20 estimators')
# Plot the resu et")
plt.title("Bagging of Decision Tree Regression")
plt.legend()
plt.show()
Gradient Bossting¶
Es un algoritmo de Boosting que aproxima el problema en poco diferente al caso anterior, en lugar de ajustar los pesos de las muestras, el Gradient Boosting se enfoca en la diferencia entre la predicción actual y el valor deseado (ground truth). El modelo global se define de la misma manera que en el caso anterior:
Sin embargo, en este caso el algoritmo minimiza el error a través de una forma de gradiente. En el paso inicial la función \(F_0 = 0\). La función de salida en el paso \(m = 1,...,M\) está dada por:
El nuevo modelo \(f_m\) intenta minimizar la función de pérdida:
Es decir, debe entrenarse usando los valores objetivo dados por:
Estos valores se conocen como los residuales del paso \(m\). Por lo tanto el algoritmo de Gradient Boosting tiene forma de algoritmo de gradiente.
La longitud del paso en el gradiente se estima como:
\begin{equation*} \gamma_m = \arg\min_{\gamma} \sum_{i=1}^{N} L\left(y_i, F_{m-1}({\bf{x}}_i)) - \gamma f_m({\bf{x}}_i) \right) \end{equation*}
Los algoritmos para clasificación y regresión sólo difieren en la función de opérdida \(L\).
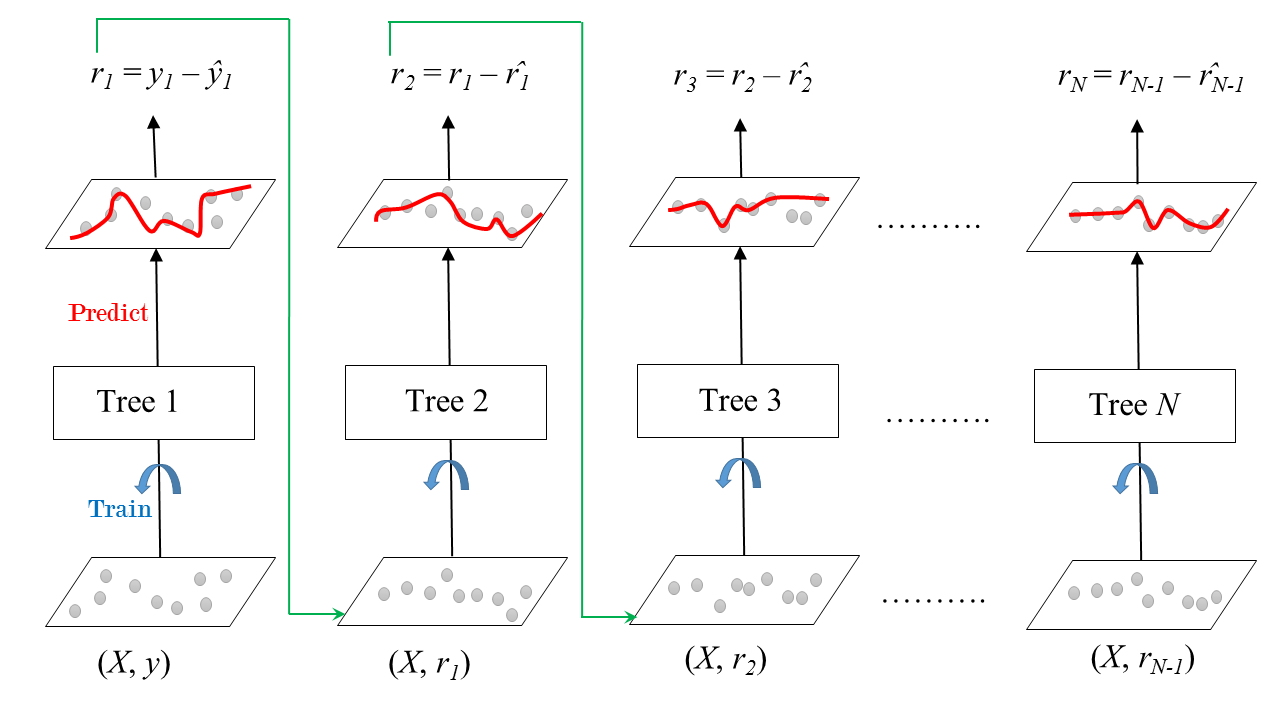
Aunque el Gradient Boosting puede ser implementado para cualquier clasificador base, el algoritmo más usado usa árboles de decisión como modelos base.
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import GradientBoostingRegressor
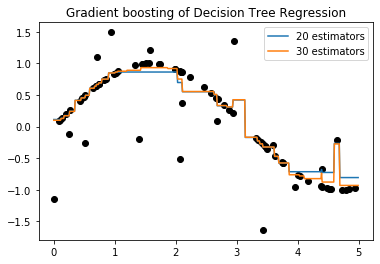
clf_1 = GradientBoostingRegressor(loss = 'lad', n_estimators=20, random_state=0).fit(X, y)
clf_2 = GradientBoostingRegressor(loss = 'lad', n_estimators=30, random_state=0).fit(X, y)
# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = clf_1.predict(X_test)
y_2 = clf_2.predict(X_test)
plt.plot(X,y,'o',color='black')
plt.plot(X_test,y_1,label='20 estimators')
plt.plot(X_test,y_2,label='30 estimators')
# Plot the resu et")
plt.title("Gradient boosting of Decision Tree Regression")
plt.legend()
plt.show()
from sklearn.datasets import load_digits
from sklearn.ensemble import GradientBoostingClassifier
digits = load_digits()
real_data = digits.data[:44].reshape((4, 11, -1))
fig, ax = plt.subplots(5, 11, subplot_kw=dict(xticks=[], yticks=[]),figsize=(15,8))
for j in range(11):
ax[4, j].set_visible(False)
for i in range(4):
im = ax[i, j].imshow(real_data[i, j].reshape((8, 8)),
cmap=plt.cm.binary, interpolation='nearest')
im.set_clim(0, 16)
ax[0, 5].set_title('Selection from the input data')
plt.show()

Performance = []
N = digits.data.shape[0]
ind = np.random.permutation(N)
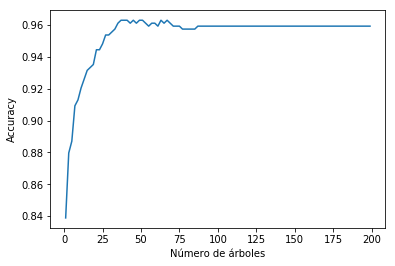
for i in range(1,200,2):
clf = GradientBoostingClassifier(n_estimators=i, max_depth=4, random_state=0)
clf = clf.fit(digits.data[ind[:int(N*0.7)],:], digits.target[ind[:int(N*0.7)]])
Performance.append(clf.score(digits.data[ind[int(N*0.7):],:], digits.target[ind[int(N*0.7):]]))
Perform = np.array(Performance)
plt.plot(np.arange(1,200,2),Perform)
plt.xlabel(u'Número de árboles')
plt.ylabel('Accuracy')
Text(0,0.5,'Accuracy')
Stacking¶
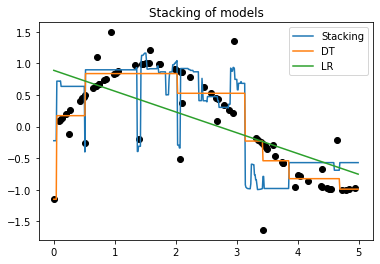
Staking es similar al primer algoritmo de ensamble descrito en la clase anterior, en el que se usan modelos base diferentes entrenados sobre el mismo conjunto de datos. Sin embargo, a diferencia del ensamble de modelos en el que la decisión final se toma en consenso entre los clasificadores base (voting), en Stacking la combinación de los modelos se realiza usando un modelo adicional (meta-modelo), en un areglo de dos capas. En la primera capa se entrenan los modelos base y en la segunda se entrena un nuevo modelo que toma como entradas las salidas de los modelos en la primera capa y produce la decisión final.

from sklearn.ensemble import StackingClassifier
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
clf_a = DecisionTreeRegressor(max_depth=3)
clf_b = DecisionTreeRegressor(max_depth=5)
clf_c = LinearRegression()
estimators = [('DT1', clf_a), ('DT2', clf_b), ('lr', clf_c)]
clf = StackingRegressor(estimators=estimators,
final_estimator=RandomForestRegressor(n_estimators=10, random_state=42)).fit(X, y)
# Predict
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]
y_1 = clf.predict(X_test)
y_2 = clf.estimators_[0].predict(X_test)
y_3 = clf.estimators_[2].predict(X_test)
plt.plot(X,y,'o',color='black')
plt.plot(X_test,y_1,label='Stacking')
plt.plot(X_test,y_2,label='DT')
plt.plot(X_test,y_3,label='LR')
# Plot the resu et")
plt.title("Stacking of models")
plt.legend()
plt.show()
clf
StackingRegressor(cv=None,
estimators=[('DT1',
DecisionTreeRegressor(ccp_alpha=0.0,
criterion='mse',
max_depth=3,
max_features=None,
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
presort='deprecated',
random_state=None,
splitter='best')),
('DT2',
DecisionTreeRegressor...
final_estimator=RandomForestRegressor(bootstrap=True,
ccp_alpha=0.0,
criterion='mse',
max_depth=None,
max_features='auto',
max_leaf_nodes=None,
max_samples=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators=10,
n_jobs=None,
oob_score=False,
random_state=42,
verbose=0,
warm_start=False),
n_jobs=None, passthrough=False, verbose=0)
Consultar¶
Stochastic Gradient Boosting Tree
Modificaciones recientes de gran interés:
XGBoost
LightGBM
CatBoost